
To Dare Is To Do!
피드 조회(feat 성능 개선) 본문
팔로우 기능을 추가됨으로써 로그인한 회원이 팔로우한 회원의 글을 모아보는 피드 또한 제공하게 되었다.
이러한 기능을 구현하고 최적화하는 과정에서 경험한 것들을 기록하여 다시 한번 정리해보려고 한다.
1. 단순 기능 구현
일단 성능에 대한 고려 없이 기능에 대한 구현만 진행해 보았다.
// PostController
@GetMapping("/followed")
public Response<List<PostResponse>> getPostsFromFollowedUsers(Authentication authentication) {
List<PostResponse> posts = postService.getPostsFromFollowedUsers(authentication.getName());
return Response.success(posts);
}
// PostService
public List<PostResponse> getPostsFromFollowedUsers(String userName) {
UserEntity user = getUserEntityOrException(userName);
// 팔로우한 사용자 목록 조회
List<FollowEntity> followedUsers = followEntityRepository.findByFollower(user);
// 팔로우한 사용자 목록 추출
List<UserEntity> followedUserEntities = followedUsers.stream()
.map(FollowEntity::getFollowing)
.toList();
// 팔로우한 사용자들의 글 조회
return postEntityRepository.findByUserIn(followedUserEntities);
}
private UserEntity getUserEntityOrException(String userName) {
return userEntityRepository.findByUserName(userName).orElseThrow(() ->
new SnsApplicationException(ErrorCode.USER_NOT_FOUND, String.format("%s not founded", userName)));
}
//FollowEntityRepository
List<FollowEntity> findByFollower(UserEntity user);
//PostEntityRepository
List<PostEntity> findByUserIn(List<UserEntity> users);
1. 팔로우한 사용자 목록 조회
먼저, followEntityRepository.findByFollower(user)를 호출하여 로그인한 사용자가 팔로우한 사용자 목록을 DB에서 조회하였다.
이때 발생하는 쿼리는 다음과 같다
SELECT *
FROM follow f
WHERE f.follower_id = ?
여기서 ?에는 로그인한 회원을 검증하는 코드(getUserEntityOrException)를 거쳐 도출된 사용자의 ID 값이 들어간다.
이 쿼리는 follower_id가 해당 사용자와 일치하는 모든 팔로우 관계를 조회하게 된다.
2. 팔로우한 사용자들의 글 조회
팔로우한 사용자 목록을 List<PostEntity> findByUserIn(List<UserEntity> users) 메서드를 통해 조회할 때 발생하는 쿼리는 다음과 같다
SELECT *
FROM post
WHERE user_id IN (조회된 회원 목록)
AND deleted_at IS NULL;
이 쿼리는 user_id가 팔로우한 사용자들의 ID 목록 중 하나의 회원의 모든 게시글을 조회하고, deleted_at IS NULL 조건을 통해 삭제되지 않은 글만 가져온다.
하지만 정렬 조건이 없으므로, 쿼리는 기본적으로 정렬되지 않은 상태로 데이터를 반환하게 된다.
정리
이렇게 단순 기능 구현을 진행했을 때 성능에 부정적인 영향을 미칠 수 있는 문제들이 존재한다.
1. 해당 로직이 실행되면서 두 개의 쿼리가 실행된다.
이는 DB와의 통신이 두 번 일어나 응답 지연의 원인될 수 있으며 첫 번째 쿼리에 대한 응답값을 stream 처리하여 데이터들(팔로우한 회원 목록)을 메모리로 가져오게 된다.
2. 첫 번째 쿼리에서 많은 회원이 조회되면 두 번째 쿼리의 IN 절에 많은 값이 들어가 성능에 부정적인 영향을 미칠 수 있다.
3. 정렬되지 않은 상태로 데이터를 메모리로 가져오게 되어 추후 애플리케이션 레벨에서 정렬한다면 메모리 및 CPU의 사용량을 증가시킬 수 있다.
4. 조회된 게시글을 한 번에 모두 가져온다.
2. 성능을 고려한 코드 개선
단순 기능 구현을 진행했을 때 성능에 부정적인 영향을 미칠 수 있는 코드들에 대한 개선을 진행해보자.
1. 로직을 실행했을 때 두 개의 쿼리가 실행되었던 기존 코드를 한 개의 쿼리로 처리할 수 있도록한다.
=> @Query를 통해 JPAL로 sql문을 명시하고, IN 절 대신 JOIN을 사용하여 하나의 쿼리로 통합하고 데이터들(팔로우한 회원 목록)을 메모리로 가져오는(데이터 stream 처리) 대신 DB에서 게시글 조회까지 한번에 처리한 후 응답 받는다.
2. DB에서 게시글을 조회할 때 한번에 모든 게시글을 조회하는 것이 아닌 한번에 10개 정도의 글을 조회한다.
=> 페이지네이션을 도입하여 한번에 사용하는 메모리 사용을 줄인다.
3. 조회한 게시글들에 대한 정렬을 DB단에서 수행하여 메모리로 가져온 이후에 정렬을 수행할 때 발생하는 불필요한 메모리 사용을 방지한다.
=> 명시된 JPQL에 최신순 조건을 걸어주어 정렬된 상태로 데이터를 응답받는다.
// PostController
@GetMapping("/followed")
public Response<Page<PostResponse>> getPostsFromFollowedUsers(Authentication authentication,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Pageable pageable = PageRequest.of(page, size);
return Response.success(postService.getPostsFromFollowedUsers(authentication.getName(), pageable).map(PostResponse::fromPost));
}
// PostService
public Page<Post> getPostsFromFollowedUsers(String userName, Pageable pageable) {
UserEntity user = getUserEntityOrException(userName);
return postEntityRepository.findPostsFromFollowedUsers(user, pageable).map(Post::fromEntity);
}
// PostEntityRepository
@Query("SELECT p FROM FollowEntity f " +
"JOIN PostEntity p ON p.user = f.following " +
"WHERE f.follower = :user " +
"ORDER BY p.registeredAt DESC")
Page<PostEntity> findPostsFromFollowedUsers(@Param("user") UserEntity user, Pageable pageable);
코드 개선 전후의 응답 시간
현재 조회를 위해 10만 개 정도의 더미 데이터(게시글)을 넣어두었다.
해당 API를 요청했을 때 코드의 개선이 이뤄지기 전후의 API 응답 시간은 다음과 같다.

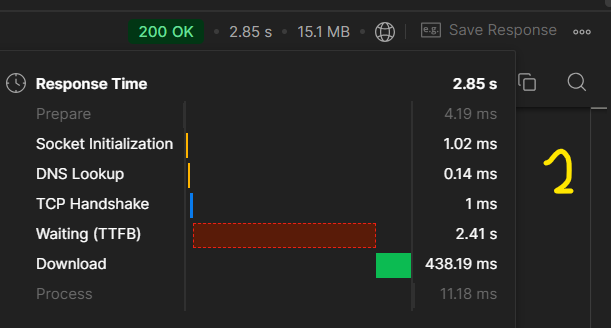

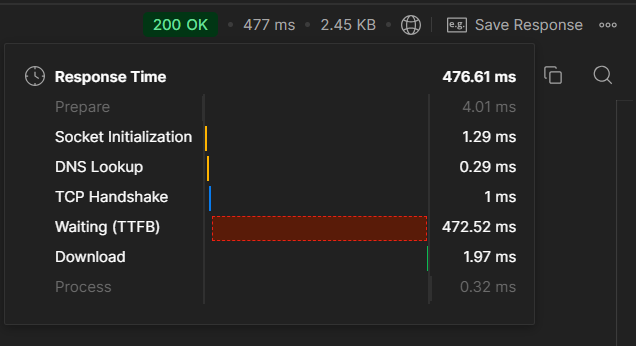
코드를 개선하기 전후의 응답시간은 약 5.5배의 차이가 나오는 것을 확인할 수 있었다.
과거 요구되는 기능을 구현하는 단계에서 마무리했던 프로젝트들이 많았는데 약간의 개선만 진행해도 생각보다 많은 차이가 나오는 것을 확인할 수 있었다.
지금은 10만 개 정도의 데이터만 다뤘는데 이보다 더 큰 데이터를 다룬다면 성능측면에서 훨씬 큰 이점을 얻을 수 있을 것이라는 생각이 드는 동시에 현업에서는 이와 비교할 수 없을만큼의 데이터를 다루는데 이 정도의 개선만으로 충분한 성능적 이점을 얻었다고 말할 수 있을까라는 생각 또한 들었다.
더 개선할 수 없을까?
인덱스 적용하기
찾아보니 인덱스를 적용하여 DB 조회 시 최적화가 가능하다는 것을 알 수 있었다.
문제는 어떤 컬럼에 인덱스를 적용할 것인지 결정하는 것인데 이 부분은 실행계획을 기반으로 결정할 수 있다.
실행 계획
실행 계획(explain)은 클라이언트가 MySQL 서버에 요청한 SQL문을 어떻게 데이터를 불러올 것인지에 관한 계획, 경로를 의미한다.
이러한 실행 계획 정보를 알 수 있다면 SQL 튜닝을 할 수 있다.
현재 JPA를 통해 DB에 질의하는 쿼리에 EXPLAIN을 추가하면 해당 쿼리의 실행 계획을 확인해보자
// 예시
EXPLAIN SELECT p.*
FROM follow f
JOIN post p ON p.user_id = f.following_id
WHERE f.follower_id = 5
ORDER BY p.registered_at DESC
LIMIT 10 OFFSET 0;
여기서 중점적으로 봐야할 부분은 type과 Extra이다.
post의 type은 ALL, Extra는 Using filesort를 확인할 수 있다.
type
MySQL이 테이블에 접근하는 방식(접근 유형)을 나타낸다.
이를 통해 인덱스를 사용했는지, 테이블을 처음부터 끝까지 스캔했는지 등의 정보를 얻을 수 있다.
ALL
테이블의 모든 행을 읽고 있다는 뜻이다. 이는 인덱스를 사용하지 않고 있음을 의미하며 이는 성능 저하로 직결된다.
Extra
쿼리 처리에 대한 추가 정보를 제공하는 부분이다. 이를 기반으로 쿼리가 실행될 때 MySql이 수행하는 추가 작업이나 최적화 방안을 작성할 수 있다.
Using filesort
정렬이 필요한 데이터를 메모리에 올리고 정렬 작업을 수행한다는 의미이다. 인덱스를 사용하지 못 할때 메모리에 올려서 filesort로 추가적인 정렬작업을 한다는 의미이므로 튜닝의 대상이 된다.
위와 같은 정보를 기반으로 특정 컬럼에 인덱스를 주는 것은 추후 N+1 문제 해결과 함께 정리해 보려고 한다.
'프로젝트' 카테고리의 다른 글
| 피드 조회 성능 개선(JPA n+1) (0) | 2024.09.22 |
|---|---|
| 피드 조회 개선하기(offset 탈출) (0) | 2024.09.08 |
| 서버가 여러 개일 때 유저 정보를 어떻게 유지할 수 있을까? (0) | 2024.08.15 |
| Nginx를 통한 Load Balancing (0) | 2024.08.09 |
| Nginx (0) | 2024.08.09 |


